

What’s big data really worth?
A working paper provides a nuanced and real-world framework for understanding how data creates value and competitive advantage


A mantra of management over the past few years has been that companies need to gather and profit from the data they collect about their customers and products. An endless stream of articles and “white papers” from consultants and tech companies present the benefits of data and analytics investments. Two common threads to many of these works are (a) the sense that one should gather as much data as possible and (b) that having the most information about customers and markets creates a competitive advantage. These beliefs have resonated so strongly that regulators (and some scholars) in the U.S. and Europe have begun to worry that excessive concentrations of information in specific markets are hindering competition and should be addressed through regulatory action.
While the idea of collecting as much data as possible sounds appealing, recent research suggests that many factors affect the value of data collected by companies. A working paper by Marco Iansiti (Harvard) summarizes those trends and—more importantly— presents a new framework for understanding the sources and dynamics of value creation through information. Supported by several case studies, his model is a welcome and nuanced perspective on how data do, and do not, create value for organizations.
Data and Competitive Advantage
As noted above, the author begins his analysis by stating that “recent literature suggests that there are a variety of factors, beyond data volume, that must be considered in order to understand the value of data and implications for competition.” These factors include “the ways in which data can drive product improvements, how learnings from data transfer across users, and whether competitors are excluded from using similar data.” While theoretical models suggest that companies can create data sets that are accurate, unique, and filled with valuable insights, the reality is that “such concentrations of informational value are the exception and not the rule.”
Moreover, the common perception that more data generate a positive feedback loop in which information begets innovation that begets more data is a questionable notion. As the author notes, while “regulatory perspective often assumes a superlinear increase in value as a function of data volume, research demonstrates that this is typically not the case.” Indeed, almost any large company's Chief Information Officer will admit that in the real world companies typically face diminishing returns to increased data volumes in many settings. I many business settings, the truth is that maximizing data collection in such conditions provides no special benefit or advantage.
In expanding on this conclusion, the author notes the lessons drawn from machine learning (ML). In general, ML applications have shown that using more data can improve system performance. This phenomenon has been particularly true in the case of deep learning, where “model performance continues to increase as a function of the size of the dataset in tasks such as machine translation, speech recognition, and computer vision.” However, the same research also shows that domain and application substantially impact this benefit curve. Indeed, the author notes that ML data sets tend to progress through three stages as they amass more information:
Stage 1: Cold Start Stage
In this stage, models improve with the addition of even small data sets, so every piece of new good data helps to improve the model.
Stage 2: Power-law Stage
In this subsequent stage, the model improves as more good data are added. Eventually, however, there are diminishing returns to data accumulation, the steepness of which is defined by a power-law exponent. Power laws, simply put, establish a relationship between two things in which a change in one thing can lead to a large change in the other, i.e., they reveal correlations between disparate factors. In applications such as ML, then, performance increases with more data but only up to a point, at which the benefit of new data begins to diminish.
Stage 3: Irreducible Error Stage
The final stage of development is one in which the addition of more data does not improve — or evens diminishes — the model’s performance. This counter-intuitive phenomenon can have several causes, e.g., model scaling up may require a huge gain in storage capacity that can result in a significant increase in latency and a similar decrease in the speed of accessing the data.
Though the three stages are common to ML models, the specific ranges vary by model depending on context. In other words, in one setting, Stage 2 may last longer than it does in another environment, which means that the point at which additional information stops adding value can vary for each ML application. Indeed, the author cites Amazon, whose researchers “found no empirical evidence of a version of data network effects in retail product forecasting, where increasing the number of products did not result in substantial improvements in demand forecasts across various lines of merchandise, beyond a small threshold.” Likewise, other research has shown that in certain applications (e.g., news personalization and video recommendations) a model’s performance actually diminishes quickly as more data is added.
Indeed, because more data does not always mean more value, new techniques — e.g., synthetic data (data generated "in the lab" to meet specific needs or certain conditions that may not be found in the original data set) and fewshot learning (using less, not more, data is used to train an ML model) — are now available that “can help firms achieve a high level of performance with a limited set of context-specific data.”
Data Value Framework
Having examined the various factors and conditions that impact how data accumulation affects value and insight creation, the author presents a new model that leaders (and regulators) can use to analyze whether and how data create a valuable competitive advantage. The framework, illustrated in Figure 1 below, has four dimensions. Each dimension is one collection of characteristics that define the value of any large data collection.
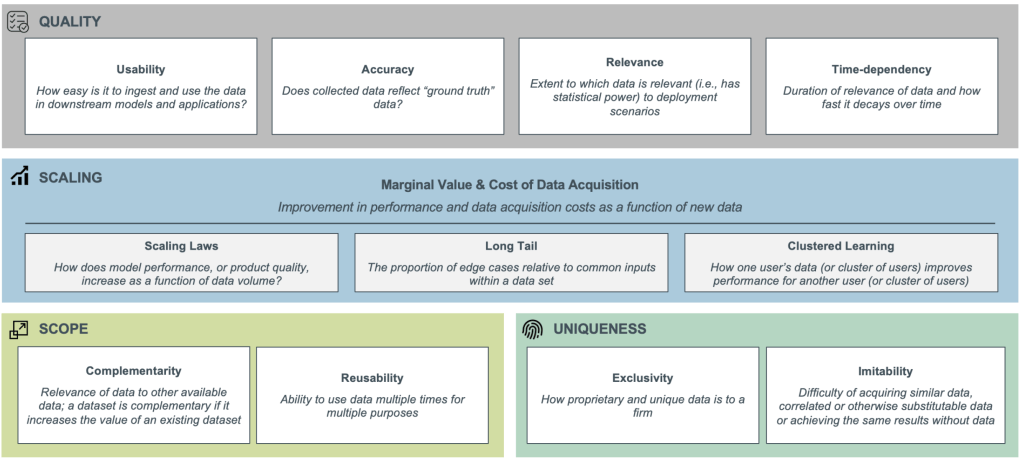
Dimension 1: Data Quality
This dimension will be of no surprise to leaders in almost any business role. Given the many challenges inherent in gathering, cleansing, and arraying good data, it is self-evident that data must be accurate and relevant to create value. Moreover, in specific settings, relevancy decays quickly with time, so it is imperative not just to gather good data but to do so sufficiently quickly. As the author notes:
For example, Facebook discovered that using stale machine learning models significantly impacted performance for a wide set of algorithms the firm deployed, including one designed to ensure community integrity (as adversaries constantly come up with new ways to display objectionable content). Algorithms that power the News Feed and Ads Ranking were also impacted significantly by stale models, withthe impact being “measured in hours” for the latter. In such cases, a limited but current set of data can result in similar, or even better, performance than a large amount of historical data, and increasing data volume by incorporating older datasets may even hurt performance.
Dimension 2: Data Scaling
As noted above, there is a point where too much information can actually diminish the performance of analytical models. The dynamics of how models scale, notes the author, are driven partially “by the fact that data often follow a long-tailed distribution (i.e., distributions that taper off gradually rather than drop-off sharply), which has implications for marginal data value and cost of data acquisition.” Thus, in settings where data age quickly, having large amounts of it in storage actually hurts competitiveness. In other words, an increasing amount of obsolete information decreases the value of the models that utilize them. This creates what economists call “diseconomies of scale,” which become worse as more and more stale data accumulate inside analytical models.
Dimension 3: Data Scope
The more insight a company can generate from a given data set, the more valuable the set becomes. Techniques such as data recombination that integrate existing data sets to create new insights expand the potential for value creation, e.g., in neural networks that aggregate different types of data to make recommendations for consumers. Thus, the degree to which a given data set can be combined or repurposed is the fourth dimension of value creation. For example, “Google uses location information not just to improve search results and personalize advertisements, but to drive research in epidemiology, natural disaster response, and infrastructure planning.” Put simply, the broader the applications of a data set, the more value it has for the data collectors.
Dimension 4. Data Uniqueness
“If data are not proprietary or do not result in learnings that are unique to a firm,” notes the author, “they cannot provide a sustainable competitive advantage.” Uniqueness is not just an inherent trait, it also refers to any unique insights an organization can produce from a given data set. In other words, even data that are available to anyone (free or for a fee) — data about weather, for example — can be used by a company to create something unique, e.g., recommendations about shipping timing. In the case where the data are unique or can be used to create a unique insight, data value as well as competitive advantage increase.
Case Studies
With his four-part framework in mind, the author presents three cases to illustrate the complex relationships between data volumes, value, and competitive advantage.
The first case is Netflix, a company justifiably famous for its extensive use of data and analytics to model customer preferences to drive programming decisions. Despite the extensive investments in data collection, as illustrated in Figure 2 below, Netflix finds itself in a brutally competitive landscape and continues to lose market share despite its long head start in the collection of data.

Indeed, Netflix may have provided the roadmap that companies such as Disney and Apple are using (and in some cases enhancing) to enter its market and grow at Netflix’s expense. Disney Plus, notes the author, “is working to identify characteristics that define repeat viewing behavior (e.g., story arcs, protagonists); taking into account the specific context of the user’s experience (for example, recommending a short if that appears to be the user’s current “mood”); and using natural language processing to analyze closed caption files to understand the “aboutness” of content and its emotional arcs. In Netflix’s market, the company with the most innovative platform draws the newest customers rather than the company with the deepest repositories of viewer data.
In a similar vein, Waymo came to life in 2009 inside of Google and quickly went on to amass the world’s largest collection of information in the field of autonomous vehicle performance. Waymo vehicles, notes the paper, “have driven over 20 million miles on public roads across 25 cities and have generated petabytes of data daily through the suite of lidar, radars, and high-resolution cameras equipped on its vehicles.” Moreover, Waymo was a pioneer in building simulation models to understand autonomous transportation’s social and behavioral dimensions. However, a decade after launch, all that data and insight have yet to make Waymo a market leader. On the contrary, its market is increasingly dominated by legacy brands such as VW, which are slowly catching up, and by new entrants like Rimac, which, as with the Disney Plus example, are using innovation to win new customers.
The final case study presented is perhaps the most interesting of the three: online advertising. To the outsider, the industry seems dominated by firms such as Alphabet that have built massive information libraries about consumer behavior online. However, the reality is that the value of advertising data “depends on many factors including data quality, complementarity with other existing data, how data drive improvements in personalization, and, in turn, when increased personalization translates into increased ad effectiveness.” In one example, notes the author, “research demonstrated that for a national apparel retailer, incorporating additional data such as demographics and ad exposure data provided essentially no performance improvements, while other types of data such as purchase history and retail-defined customer categories provided only minor improvements.” In fact, in this case, reducing data volume “by removing purchase data prior to a customer’s first ad exposure” actually increased ad performance more than new data.
Conclusions
The primary audience of this working paper is regulators who are looking with growing concern at the immense (and ever-increasing) collections of data housed in a handful of firms. Prima facie, it seems that the more data these few companies gather, the more value they create and the more secure their competitive advantage is. This effort presents an interesting — and to some people controversial — alternative viewpoint to this perspective, and its conclusions are worth consideration by business and technology leaders.
While the collection of data is generally a good thing, it is essential to understand the many complex and interrelated dimensions that ultimately determine the return on investment of any commercial data store. The four dimensions of the framework this paper presents —quality of data, scale and scope of data, and uniqueness of data— collectively define the mechanisms that create competitive advantage through information. In laying out the arguments in favor of the framework, Professor Iansiti presents a nuanced perspective on the value of investing in data, a perspective that should inform how business leaders think about this topic.
The Research
Iansiti, Marco. “The Value of Data and Its Impact on Competition.” Harvard Business School Working Paper, No. 22-002, July 2021.